

That code you’re writing right now may someday need to be translated into French or Japanese or Arabic.
Do you intend to market or use your application software internationally? If so, you may need to translate your user interface into different languages. This article gives you some hints and tips to help you facilitate the translation/software localization task, and to help you avoid some of the pitfalls that can make translation almost impossible.
Most of my comments apply whether or not you use translation tools. Some tools may help in overcoming situations in which guidelines have not been followed to make the translation process easier. As an example, some tools can identify text within programming code and therefore help you with translation even though text has not been isolated into separate files.
The more technical the application and its audience, the less need there may be to translate it or its corresponding user manuals. For instance, a programmer’s debugging toolkit is less likely to need translation than an educational product for students.
However, whether or not you’ve decided to translate the application, it is advisable to make provisions in the design with translation and software localization in mind.
Isolate Text
Isolate the translatable content into files that are separate from the programming code. If your development environment offers a native way of doing this, adhere to standard procedures rather than developing a customized solution. A customized solution may not be as easily supported as the native development environment’s standard when product enhancements and updates are released and may prevent you from using development toolkits within that development environment or not allow you to take full advantage of them.
The IBM System i platform already externalizes translatable text to some extent within its DDS facilities. DDS contains screen and report formats along with the text. Text can be isolated further by placing it into message files and specifying that the DDS refer to messages instead of embedded literals.
If you do externalize literals, take great care if you intend use the same externalized text multiple times within the application (this is covered in more detail later in this article).
If entered responses such as Y for Yes, N for No, C for Create, A for Amend, and D for Delete are to be translated, store the characters somewhere in a database file and allow the program to compare the entered response with the database character. That way, you only need to translate the responses once. An alternative solution would be to have the software determine the response characters by preceding them with a special character (e.g., &Create). Still another solution is to avoid translation altogether by having the user enter numerals; 1 for Yes and 2 for No, although that may not be considered user-friendly.
Note also that mnemonics (the single character you enter for a command, which is typically underlined in GUI applications) could occur anywhere within a translated application. Do not assume that if you can use the first character of a command in English, you will be able to do the same in other languages.
Text Length
The translations for many languages frequently exceed the length of the corresponding English source. This represents one of the biggest problems facing translators because they need to determine whether they can safely expand the text without encroaching on the next field. And if there is simply not enough room, translators must try to sensibly abbreviate the text. As a general rule of thumb, 30-50% of additional space should be allowed for translation, and even more for shorter text.
If possible, translate a prototype of your screens and reports into German and refit and resize your design based on the German translation. This will result in a design that should be translatable into just about any language with a minimal amount of length problems. If left until later, it will cost a lot more to correct, or more likely, it will not be corrected at all, and the quality of the foreign language versions will suffer.
Allow the number of panels to increase or decrease when you are displaying help text.
Stacked Literals
Avoid stacked literals such as this:
Purchase
order
The linked texts are probably remote from each other and therefore may be difficult for the translator to associate together. Also, in many languages, the sequence of words changes:
Purchase
order
becomes
order
Purchase
When this happens, a comparison of the two language files contains apparently incorrect translations (“Purchase” to “order” and “order” to “Purchase”).
Furthermore, in certain languages, order may need to have multiple “translations” (e.g., Sales, Purchase, or Shop Floor), depending on whether the stacked text is Sales order, Purchase order, or Shop Floor order. These “alternative translations” create havoc within the translation memory tools that most professional translators use and will result in significant and costly additional effort in translating new releases. Potentially, the same stacked literals may need identifying and reworking each time they are translated.
Side-by-side literals (Purchase and order as two texts instead of one text, Purchase order) are a variation of stacked literals and are to be avoided for the same reasons.
Dynamic Messages
Literals may contain run time variables, such as this:
Invoice total $2000.00 exceeds the $1500.00 available credit by $500.00
Do not make this three texts (Invoice total, exceeds the, and available credit by) with inserted values. This variation of the side-by-side literal is tempting to split into three texts because of the variables. However, the syntax of certain foreign languages may require a completely different sentence structure that requires the values to be placed in a different sequence.
The prudent solution is to make it one text segment with special character values (tokens) to indicate where the variables should be. The program should then search for the tokens and substitute the run-time variables. So a text segment resembling the example below should work fine:
Invoice total AAAAAAAAA exceeds the BBBBBBBBB available credit by CCCCCCCCC
Be careful to use tokens (like the A’s, B’s and C’s) that are not code page-dependent and are not likely to occur naturally in the text of any language (some development environments allow you to specify real program variables within text). Be sure to document their use.
Sentence/Phrase Construction
Do not build sentences from discrete phrases. The following phrase should be one long literal even though it results in some text duplication:
Select the following options, then press ENTER.
Do not economize by splitting it into smaller phrases (Select the following options, and then press ENTER) with the intention to reuse the phrases in different sentences. This will not work in languages with different sentence structures.
Similarly, if you externalize text into message files (for example), be very careful if you decide to use the same literal multiple times.
For example, do not use different parts or lengths of the same literal in multiple places. The following literal should be used only when displaying debit and credit together.
“ Debit Credit ”
Do not rely on picking out the individual words Debit and Credit because they will be translated to different lengths and may start in different positions.
Be sure that the length and the meaning of shared literals are exactly the same. English is less precise than most languages. For example, “bolt” can mean to run or to eat quickly. It can also be something that screws into a nut, something that locks a door, or a stroke of lightning. Most languages would use completely different words for each of these expressions.
Another example is the expression Enter order number. If this is used as a prompt for different types of orders (purchase orders, sales orders, shop floor orders), each type of order should have its own prompt.
If it is not possible to avoid stacked literals, you must hold all parts of stacked literals separately for each occurrence; otherwise, your application may be incapable of translation. If order is held only once, it cannot be translated to Sales in one stacked literal and to Purchase in another.
Where the same text can have different lengths depending on where in the application it is used (for example, when some screens have more free space than others), hold it as a separate literal for each length, even though this results in duplication. When translated, it may need to be abbreviated or abbreviated differently, depending on the available length.
Do not rely on the fact that truncating a few characters yields a good abbreviation.
Define column headings as one long literal rather than as separate literals per column. That way, the heading of a small column can be expanded left and right over its neighbors if necessary and even combined with other headings.
Identify Screens and Panels
Your support organization may be working in a different language than the users are and may not understand a problem being reported on a translated screen or message. One solution is to be able to dynamically switch from one language to another. However, that may be impossible with some combinations of code pages. It is therefore advisable to uniquely and numerically identify each screen and error message. If these numbers negatively impact normal operation, consider placing them in a pop-up window.
Translation Tips
- If the translators don’t already have one, provide them with a keyboard for the language they’re translating into so that they can more quickly and easily enter accented characters.
- Avoid colloquial expressions and abbreviations wherever possible. Both can be extremely difficult and time-consuming to translate.
- Keep the text simple, and use simple sentence construction in manuals. Keep sentences short.
- Be consistent in your English terminology, even if it is repetitious. If you Press Enter, don’t sometimes Depress, Select, or even Hit it!
- Translators need to know not only what the text is, but also how long it can be. So always allow as much room as possible for your literals and pad them out with spaces. Or include comments or identify another way for the translators to know how much room they have to work with. It is probably better, however, to pad out the literals with spaces so that the translator does not need to change the defined length of the literal.
- Do not split texts. Allow one long text segment for a heading line. Do not split phrases into words.
Language Types
Here are examples of the different language types that you should be aware of.
Conventional Left-to-Right
Conventional left-to-right languages include English, Spanish, French, and German. Although you may require a different code page, a standard American QWERTY keyboard can be used with PCs. But a foreign-language keyboard is helpful because it contains the accented characters.
Other left-to-right languages, such as Russian, Greek, and Thai, are less conventional. Russian and Greek must have their own code pages, and the appropriate keyboard with the correct diacritics is strongly recommended. Although keyboards can generally be configured through software to conform to different character sets, the key engravings would not correspond to the actual typed characters (making typing difficult for non-touch typists).
Thai, like Chinese and Vietnamese, is a tonal language: The same word can have a completely different meaning depending on how it is pronounced. Thai has five tones: mid tone, high tone, low tone, rising tone, and falling tone. If each tone-character combination had its own character within the Thai code page, there would be more characters than the 256 available. The tone therefore is held as a separate character. Thai operating systems generally detect the tone and superimpose the tone on its associated character. This means that because toned characters require two bytes, Thai needs more storage space for text than would be apparent from the number of displayed or printed characters.
Bi-directional Languages
Bi-directional languages are Arabic, Hebrew, and Farsi. The text is generally written from right to left, and the entire screen image is reversed. So a typical line on an Arabic screen would start in position 80: for example, Account number (or whatever the field prompt is) with the account number itself to the left of it.
You generally need to rework the DDS by basically developing a mirror image of the English screen.
Bi-directional languages can also contain left-to-right strings; hence they are called “bi-directional”. Left-to-right strings include numbers when written in Roman characters (numbers can also be expressed in right-to-left Arabic characters). Left-to-right strings can also include Roman character names and keyboard diacritics. To switch between modes, a function key toggles between right-to-left and left-to-right entry (Arabic mode and Latin mode, respectively).
Arabic is a script language requiring character shaping. Similar to connected cursive English, the character assumes a different shape depending on whether it occurs at the beginning, middle, or end of a word or as a standalone character. Some characters can have four shapes: isolated, initial, middle, and final. There is also a base form that is used to represent the character without shaping and an input form in which characters may be entered (but those characters do not represent valid, correctly shaped forms). As you type, characters change shape as other characters are added to them or the word is terminated.
Although Arabic is not a double-byte language, some shaped characters can occupy two positions on the screen. (See Figures 1 and 2 below.)
Figure 1: This is the Arabic screen.

Figure 2: And this is the corresponding English screen.
Double-Byte Character Set (DBCS) Languages
DBCS languages are Simplified Chinese, Traditional Chinese, Korean, and Japanese. Each character generally represents a word and, because there are over 7000 of them in Japanese, two bytes are required to display each character. Chinese, Japanese, and Korean can all be written in vertical columns from top to bottom and right to left or, like English, top to bottom and left to right. On most computer systems, only top to bottom and left to right is supported.
As with Arabic (and for the same reasons), there can be embedded Roman strings of proper names and keyboard diacritics.
Japanese consists of three alphabets:
- Kanji (double-byte characters)
- Hiragana (double-byte, phonetic characters)
- Katakana (single-byte or double-byte, phonetic characters)
Because of the single-byte alphabets and the need to be able to include Roman characters, you must to be able to toggle between single- and double-byte characters within a phrase. On the iSeries, this is accomplished by preceding double-byte strings with a shift-out character and terminating them with a shift-in character (the user “shifts out” of single-byte mode to enter DBCS characters and, when done, “shifts in” to return to single-byte mode).
This also means that the minimum size for a field that can contain one double-byte character is four bytes: one byte is used for the shift-out character, two bytes for the character itself, and one byte for the shift-in character. Therefore, some database fields that currently store a small number of characters may need to be expanded in the DBCS environment. However, coded data such as 1 for Female or 2 for Male does not require toggling, even though your application may display the double-byte equivalent of M or F.
To enter a double-byte character, you first hit the function key that indicates that you are entering a double-byte character. Next, you type the character phonetically and hit the spacebar. The system will display a numbered list of characters that sound like what you have entered. You then select (by number) the character you want. Although this gives you the equivalent of a word, it is somewhat cumbersome, and simple responses like Y and N for Yes and No would not normally be translated, as it is easier to type the response in English!
Generally, unless the field is small, double-byte language translations do not expand the same way some languages (e.g., German) do, and they generally require no more space than the English source.
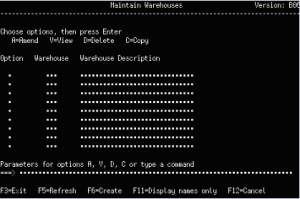
Figures 3 and 4 represent a Japanese screen and its corresponding English screen, respectively.
Figure 3: Here’s the Japanese screen.
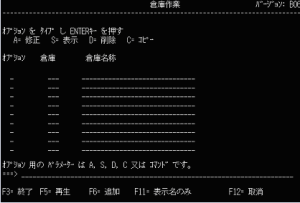
Figure 4: And here’s the corresponding English screen.
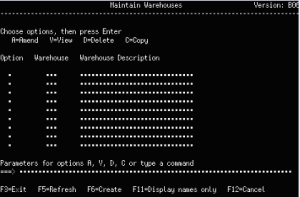
Expanding Your Horizons
Maybe you’re planning to move your software into other countries, and maybe you’re not. But you never know what changes could be right around the corner. Treat all the code you write as though translation is a possibility and keep your options open.
This article was originally published by MC Press in MC Mag online.